

説明しています。
.
「IMPORTXML関数」は
スクレイピングにとても役立つ関数なので
ぜひ、参考にしてくださいね。
※スクレイピングの詳細はコチラ!
うーん、Webサイト上のデータを
リストにしていきたいけど大変だ…。
もしかして、コピペしてない??
うん、してる。
でも、量も多いし、漏れもありそうで不安。
実は、データを簡単に取得できる
関数があるよ!
え、何それ
知りたい!
【IMPORTXML関数とは】
▶︎IMPORTXML関数
この関数を使用すると、WEB上の情報を取得して
スプレッドシートに表示することができます。
具体的には、指定したURLからXMLデータを抽出し、
データの要素や属性を指定して取得することが可能です。
url:取得したいデータが存在するウェブページのURLを指定します。
XPath:取得したいデータの場所をXPathクエリで指定します。
▶︎XPathの取得
ここではGoogle Chromeでの
取得方法を説明します。
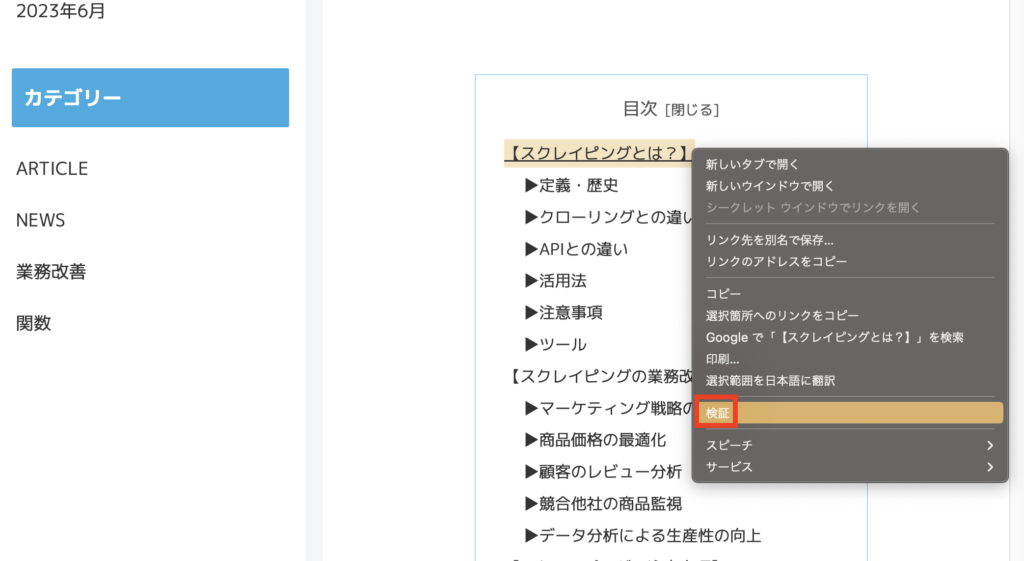
1:「検証」を選択
取得したい情報を右クリックし
「検証」を選択します。
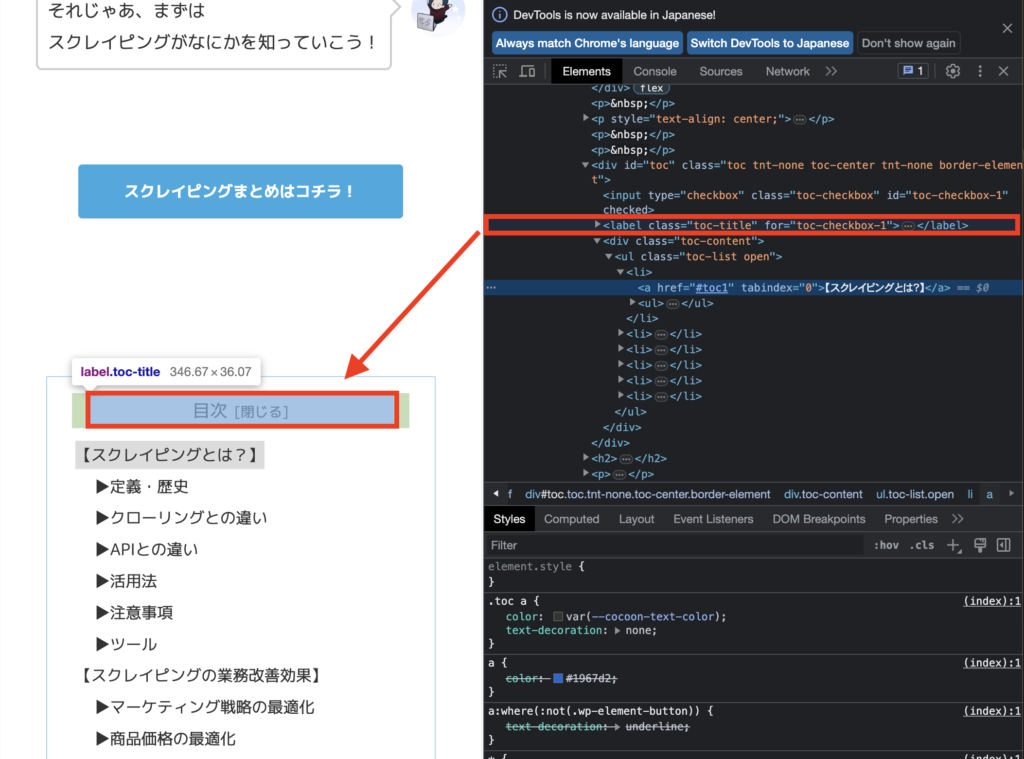
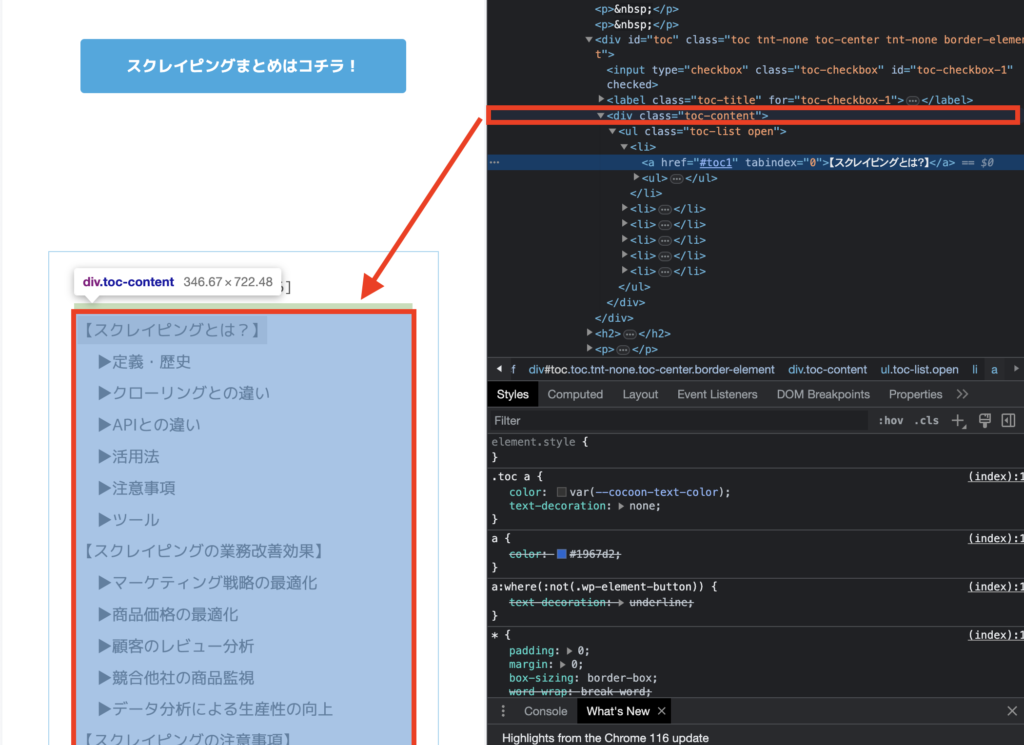
2:取得したい情報を選択する
構文にカーソルを合わせると
下記のように取得できる情報に色がつくので
より細かく取得したい情報を選択します。
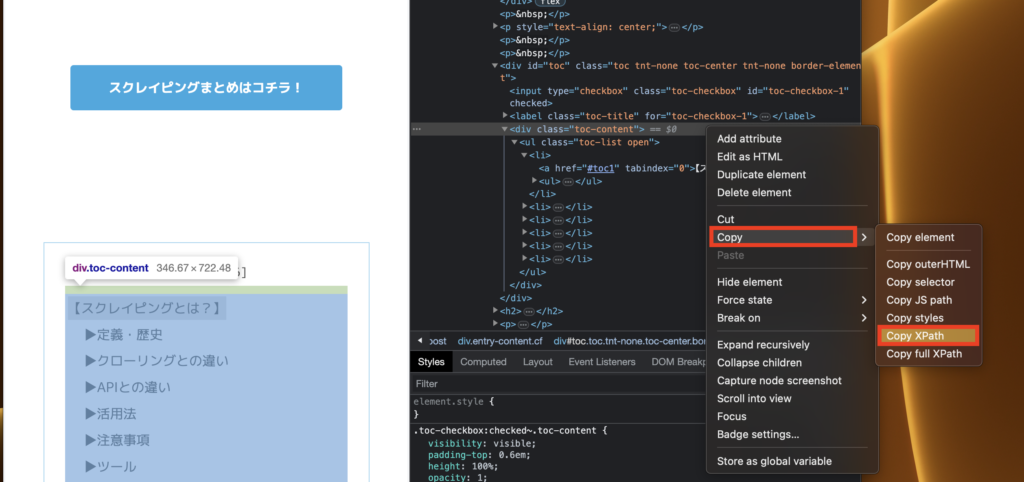
3:「Copy XPath」を選択
取得したい構文(情報)を
右クリック→「Copy」→「Copy XPath」選択します。
4:スプレッドシート等に貼る
Xpathがクリップボードにコピーされた状態なので
上書きされる前にスプレッドシート等に貼っておきます。
※3でコピーされたXPath ↓↓
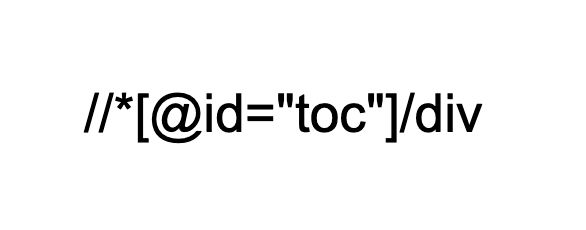
代行に頼むのも1つの手段!

▶︎IMPORTXML関数の使い方
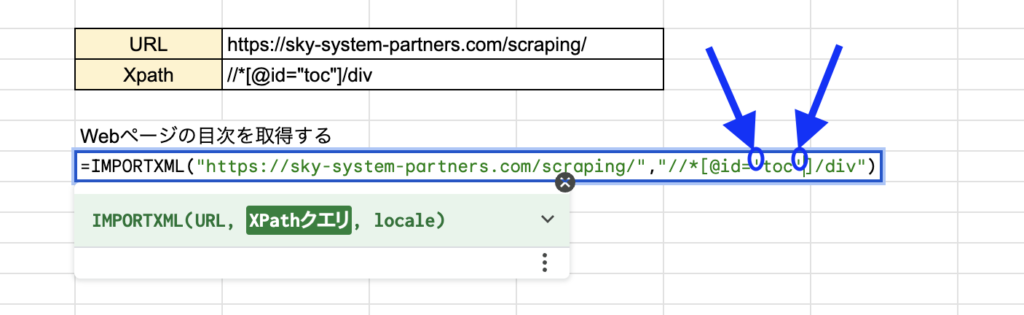
URLを取得する
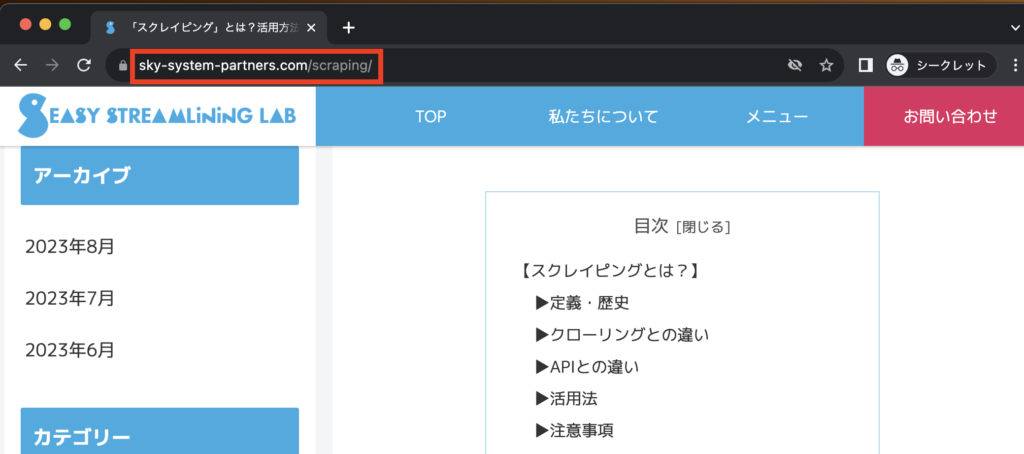
スプレッドシートに貼っておきます。

XPathを取得する
取得方法の詳細はコチラ▶︎▶︎▶︎XPathの取得
こちらもスプレッドシートに貼っておきます。
関数を組む
URLを入力して
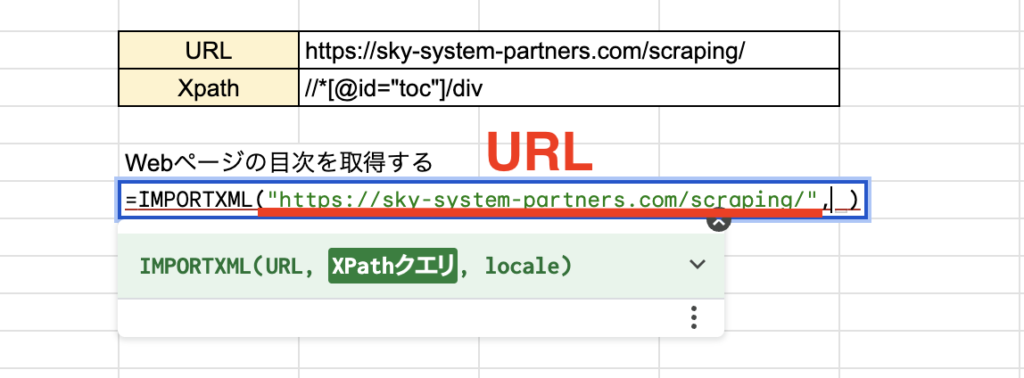
XPathを入力すると
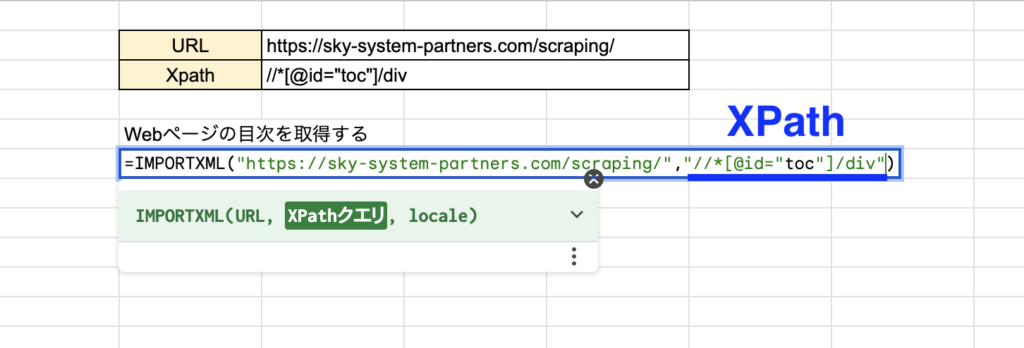
エラーが出てしまいました…


▶︎IMPORTXML関数の注意点
- 取得するデータが存在しない場合や、ウェブページの構造が変更された場合はエラーが表示されます。
. - 取得したデータは静的なものであり、自動的に更新されないため、定期的に関数を再計算して最新のデータを取得する必要があります。
. - ウェブページの読み込みに時間がかかる場合や、取得するデータの量が多い場合は処理時間が長くなる可能性があります。
IMPORTXML関数について、簡単に紹介しましたが
いかがだったでしょうか??
もし、難しそう…大変そう…と感じた方は
私たちで代行することもできます!
問い合わせはコチラ
【IMPORTXML関数の使用用途】
IMPORTXML関数は、Googleスプレッドシート上で
ウェブページから情報を取得するための便利な機能です。
▶︎記事等からタイトルや本文を取得する
特定のウェブサイトのURLと適切なXPathクエリを指定することで、
記事のタイトルや本文などのテキストデータをスプレッドシートに取り込むことができます。
これにより、ウェブ上の記事を集約して分析や比較を行ったり、
特定のキーワードが含まれる記事を抽出するなどの作業が容易になります。
▶︎外部APIからデータを取得する
IMPORTXML関数は、XML形式のデータだけでなく、
ウェブサービスのAPIからJSON形式のデータを取得することも可能です。
APIエンドポイントのURLを指定し、必要なデータを適切に解析することで、
リアルタイムの情報や外部データをスプレッドシートに統合することができます。
▶︎株価や為替レートの自動取得
株価や為替レートなどの金融データは、ウェブ上で提供されていることが一般的です。
IMPORTXML関数を使用して、金融関連のウェブサイトから必要なデータを抽出し、
スプレッドシート上でリアルタイムに表示・更新することができます。
これにより、投資や予算管理などの金融関連の作業を効率化することができます。
▶︎商品価格の比較やモニタリング
オンラインショッピングサイトなどから商品の価格情報を取得し、
スプレッドシート上で比較やモニタリングを行うことができます。
価格変動を把握したり、最安値や最高値を自動的に更新したりすることで、
効果的な商品の選定や購買計画の立案が可能となります。
【IMPORTXML関数の使い方の例】
関数の使い方を私たちのHP(https://sky-system-partners.com/)
を例に説明していきます!
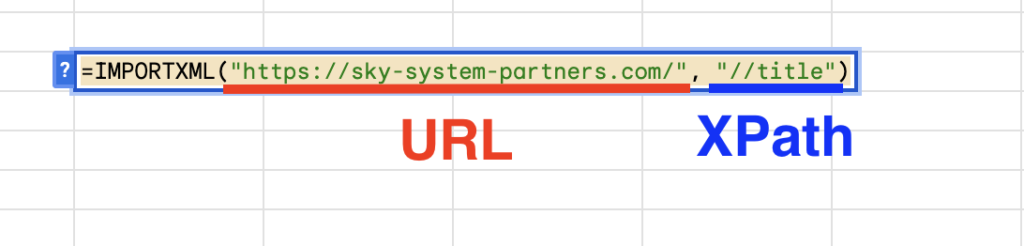
▶︎例1:ウェブページのタイトルを取得する
この例では、指定したURLのウェブページのタイトル要素のテキストを取得します。

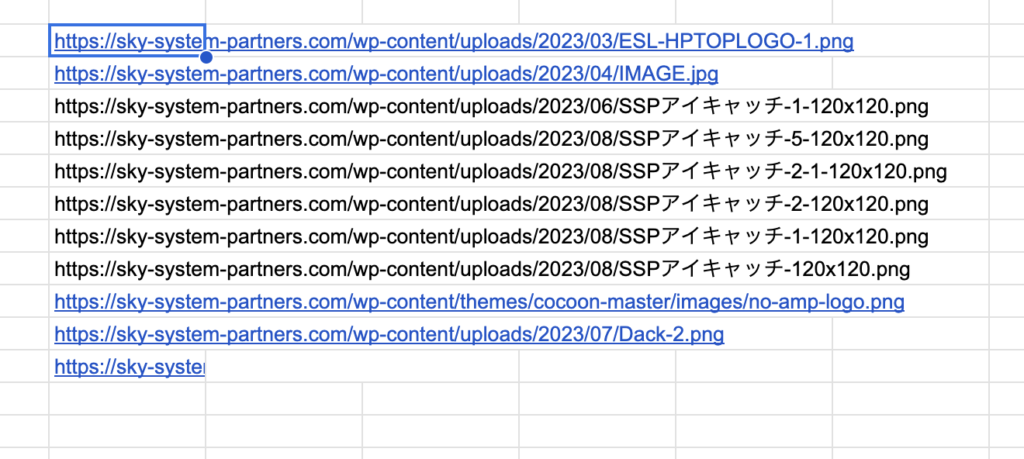
▶︎例2:画像のURLを取得する
この例では、指定したURLのウェブページ内の全ての
img要素のsrc属性の値(画像のURL)を取得します。

【Pythonを使ったスクレイピングとの違い】
この章では、Pythonを使ったスクレイピングと
IMPORTXML関数の違いについて説明します。
▶︎Pythonを使ったスクレイピング
プログラミング言語Pythonを利用してウェブサイトから情報を取得する方法です。
一般的には、PythonのライブラリであるBeautiful SoupやRequestsなどを使用して、
ウェブサイトのHTMLを解析し、必要なデータを抽出します。
スクレイピングは柔軟性があり、ほぼすべてのウェブサイトからデータを収集できますが、
プログラミングスキルが必要であり、比較的複雑な作業となることがあります。
▶︎IMPORTXML関数
Googleスプレッドシートの組み込み関数の1つであり、
ウェブページのデータを取得するために使用されます。
IMPORTXML関数はXPathを使用して特定の要素や属性を抽出することができます。
スプレッドシートユーザーにとっては、プログラムを書く必要がなく、
直感的な関数の使用でウェブデータを取得できる点が魅力です。
ただし、IMPORTXML関数は特定のウェブサイトにのみ対応しており、
複雑な操作や大量のデータを取得することには限界があります。
▶︎メリット・デメリット
Pythonを使ったスクレイピングのメリットは、柔軟性と自由度が高いことです。
Pythonの豊富なライブラリを駆使して、ウェブサイトから必要な情報を効率的に取得できます。
また、ログインが必要なサイトやJavaScriptが動的に生成するサイトなども
対応できる点が強みです。
一方、IMPORTXML関数のメリットは、手軽さと簡単さです。
ウェブデータを取得するためにプログラムを書く必要がなく、
直感的な関数で簡単にデータを取得できます。
また、スプレッドシート内で取得したデータを直接加工や集計できるため、
分析や可視化にも便利です。
しかし、IMPORTXML関数は対応している
ウェブサイトに制限がありますし、データの取得に制約がある場合もあります。
また、スクレイピングに比べると取得速度も遅い場合があります。
<Pythonを使ったスクレイピングとIMPORTXML関数>
| メリット | デメリット | |
| Python | 柔軟性と自由度が高い |
– |
| IMPORTXML関数 | 手軽さと簡単さ | ウェブサイトやデータの取得に制約がある |
結論として、Pythonを使ったスクレイピングは柔軟性と自由度が高く、
より複雑な操作や大量のデータ取得に向いています。
一方、IMPORTXML関数は手軽さと簡単さがあり、
ウェブデータの基本的な取得やスプレッドシートでの集計や分析に適しています。
【IMPORTXML関数 まとめ】
▶︎IMPORTXML関数とは
IMPORTXML関数
この関数を使用すると、WEB上の情報を取得して
スプレッドシートに表示することができます。
url:取得したいデータが存在するウェブページのURLを指定します。
XPath:取得したいデータの場所をXPathクエリで指定します。
XPathの取得
ここではGoogle Chromeでの
取得方法を説明します。
1:「検証」を選択
取得したい情報を右クリックし
「検証」を選択します。
2:「Copy XPath」を選択
取得したい構文(情報)を
右クリック→「Copy」→「Copy XPath」選択します。
代行に頼むのも1つの手段!
IMPORTXML関数の使い方
URLを取得する
スプレッドシートに貼っておきます。
XPathを取得する
取得方法の詳細はコチラ▶︎▶︎▶︎XPathの取得
こちらもスプレッドシートに貼っておきます。
関数を組む
URLを入力して
XPathを入力すると
エラーが出てしまいました…
IMPORTXML関数について、簡単に紹介しましたが
いかがだったでしょうか??
もし、難しそう…大変そう…と感じた方は
私たちで代行することもできます!
問い合わせはコチラ
▶︎IMPORTXML関数の使い方の例
関数の使い方を私たちのHP(https://sky-system-partners.com/)
を例に説明していきます!
例1:ウェブページのタイトルを取得する
この例では、指定したURLのウェブページのタイトル要素のテキストを取得します。
例2:画像のURLを取得する
この例では、指定したURLのウェブページ内の全ての
img要素のsrc属性の値(画像のURL)を取得します。
▶︎PythonとIMPORTXLM関数
この章では、Pythonを使ったスクレイピングと
IMPORTXML関数の違いについて説明します。
Pythonを使ったスクレイピング
プログラミング言語Pythonを利用してウェブサイトから情報を取得する方法です。
一般的には、PythonのライブラリであるBeautiful SoupやRequestsなどを使用して、
ウェブサイトのHTMLを解析し、必要なデータを抽出します。
IMPORTXML関数
Googleスプレッドシートの組み込み関数の1つであり、
ウェブページのデータを取得するために使用されます
<Pythonを使ったスクレイピングとIMPORTXML関数>
| メリット | デメリット | |
| Python | 柔軟性と自由度が高い |
– |
| IMPORTXML関数 | 手軽さと簡単さ | ウェブサイトやデータの取得に制約がある |
結論として、Pythonを使ったスクレイピングは柔軟性と自由度が高く、
より複雑な操作や大量のデータ取得に向いています。
一方、IMPORTXML関数は手軽さと簡単さがあり、
ウェブデータの基本的な取得やスプレッドシートでの集計や分析に適しています。
関数でWeb情報を
取得できるなんてすごいな!
でしょ!手軽にできていいよね。
これから活用できそう??
正直、シンプルなのはできそうだけど
複雑になると自信ないな…。


